



Harnessing LLMs for web research offers significant gains, but success demands understanding their strengths, limitations, and the interplay between commercial products and custom agent development
📌 TL;DR
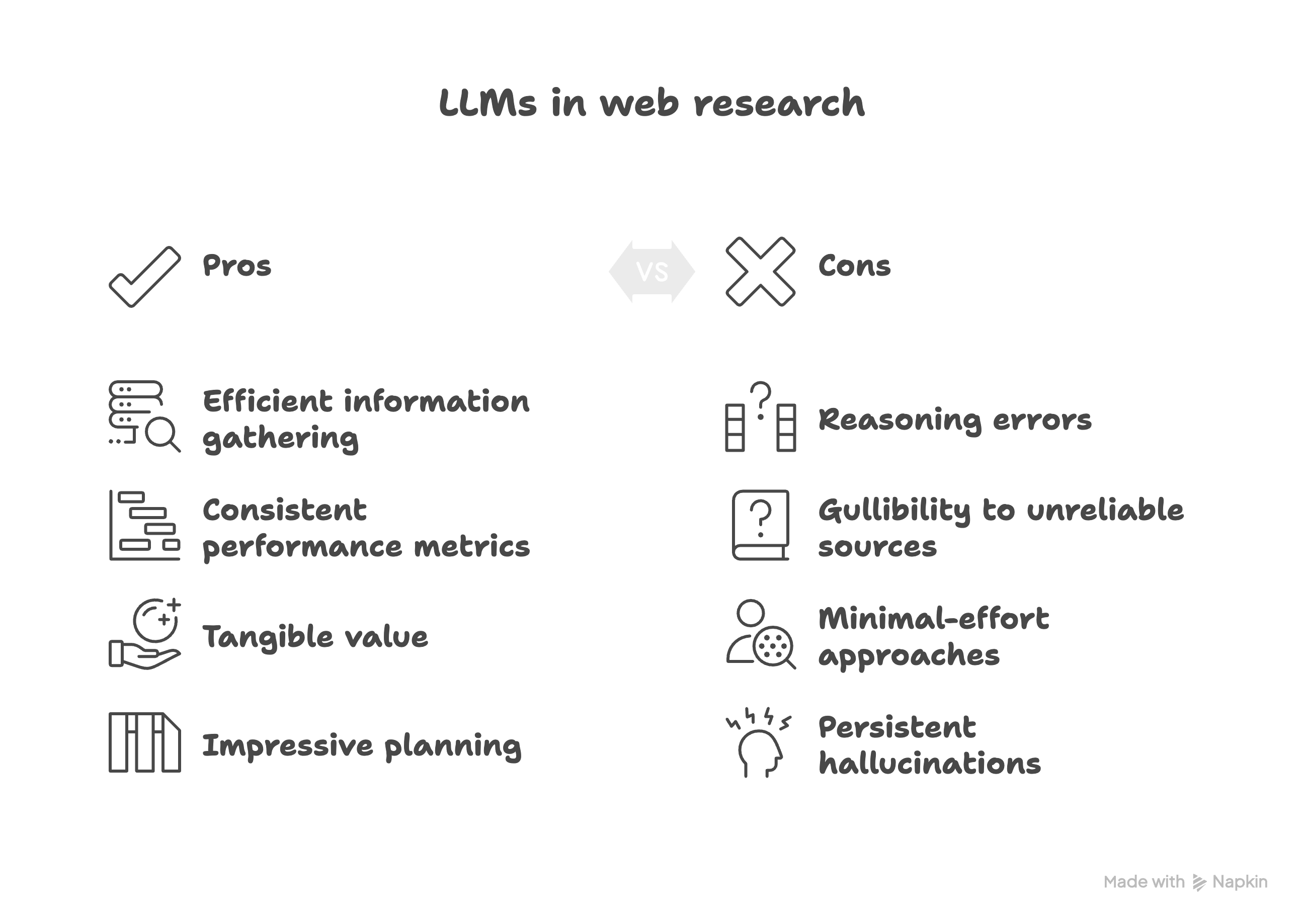
The integration of LLMs into web research has transformed how we gather information, making tools like chatbots a primary starting point for complex queries. FutureSearch's Deep Research Bench (DRB) provides a robust framework to evaluate these capabilities using frozen internet snapshots, offering consistent performance metrics. While LLM agents deliver tangible value and can develop impressive plans for difficult problems, they currently lag behind skilled human researchers, exhibiting common failure modes such as reasoning errors, gullibility to unreliable sources, minimal-effort approaches, and persistent hallucinations. The implication is clear: judicious adoption of leading commercial tools (like ChatGPT with web search) is crucial, alongside a forward-looking perspective on developing custom API-driven agents where higher performance (e.g., with Claude 4) or specific capabilities (like PDF reading) are paramount. Understanding these nuances is key to optimizing current research workflows and designing the next generation of AI-powered research assistants.
📚 Sources
A Guide For LLM-Assisted Web Research by Nikos I. Bosse, Dan Schwarz, Lawrence Phillips, FutureSearch
Deep Research Bench: Evaluating AI Web Research Agents by FutureSearch, Nikos I. Bosse, Jon Evans, Robert G. Gambee, Daniel Hnyk, Peter Mühlbacher, Lawrence Phillips, Dan Schwarz, Jack Wildman
🧩 Key Terms
LLM-assisted web research: The practice of utilizing Large Language Models (LLMs) to facilitate and enhance the process of finding, extracting, and synthesizing information from the internet. Think of it as having a highly intelligent research assistant that can rapidly comb through vast amounts of online data.
Deep Research Bench (DRB): A specialized benchmark developed by FutureSearch to evaluate the effectiveness of LLM agents in performing challenging, multi-step web research tasks. It acts as a standardized testing ground to compare different AI models.
RetroSearch: An innovative system underpinning DRB that provides LLM agents with a "frozen" or static version of the internet, scraped and stored offline. This eliminates variability from the constantly changing live web, ensuring that benchmark results are consistent and comparable over time.
ReAct agent: A common architecture for LLM agents (short for "Reason + Act") where the LLM continuously cycles through a loop of internal "thought" (reasoning), selecting an "action" (e.g., a search query or reading a document), and observing the outcome of that action. It's like a detective who thinks, then acts, then observes, and thinks again.
Hallucination: A critical failure mode where an LLM generates information that sounds plausible and factual but is entirely incorrect, fabricated, or not supported by its sources. It's the AI equivalent of making up facts.
Epistemics: The branch of philosophy concerned with the theory of knowledge, particularly with its methods, validity, and scope, and the distinction between justified belief and opinion. In the context of LLMs, it relates to how reliably and accurately they acquire and process information.
Commercial web research tools: User-facing products (e.g., ChatGPT with web search, Perplexity Pro) that integrate LLMs directly with web browsing capabilities, often branded as "Search," "Research," or "Deep Search" tools. These are off-the-shelf solutions.
API-driven agents: LLMs accessed programmatically through an Application Programming Interface (API), allowing developers to build custom agent architectures and integrate the LLM's capabilities into bespoke applications. This offers greater control and customization than commercial products.
Low-elicitation prompting: A method of instructing LLM agents using simple, concise prompts without excessive detail or explicit guidance on how to optimize results. This approach aims to reveal the model's inherent problem-solving tendencies under realistic user interactions.
Satisficement vs. optimization: The tendency for an LLM to accept the "first good enough" solution it finds (satisficement) rather than striving for the absolute best or most comprehensive answer (optimization), especially when given low-elicitation prompts.
💡 Key Insights
ChatGPT o3 with web search is the current commercial leader: Among commercial web research tools, ChatGPT with o3 + web search demonstrably outperformed all other tested approaches by a comfortable margin. Its tendency to double-check its findings likely contributes to its higher scores. This positions it as the recommended default for general research tasks.
Custom agent development shines with Claude 4: For organizations building their own web agents via API, Claude 4 Sonnet and Opus emerged as superior, outperforming o3, Claude 3.7, and Gemini 2.5 Pro. This highlights the significant return on investment for those willing to develop custom architectures around these top-tier models.
"Deep Research" modes often underperform standard chat interfaces: Counterintuitively, regular chat models with web search capabilities often outperformed their corresponding dedicated "Deep Research" tools (e.g., ChatGPT o3 vs. OpenAI Deep Research, Perplexity Pro vs. Perplexity Deep Research). These standard modes are also generally faster and more conducive to iterative research. Gemini Deep Research was a notable exception, performing better than its standard counterpart.
LLMs still trail human experts: Despite significant advancements, frontier LLM agents underperform skilled human researchers on difficult open-web research tasks, especially concerning systematic planning, thoroughness, and adaptability. This underscores the enduring value of human oversight and expertise.
Persistent failure modes demand vigilance: LLMs continue to exhibit critical failure modes: they make reasoning errors, are often gullible to unreliable information, tend to adopt minimal-effort approaches, struggle with nuanced Google queries, and still hallucinate plausibly. DeepSeek R1 was particularly prone to hallucinations.
PDF reading capability is a performance differentiator: The inability of some models, such as Claude (as of May 6, 2025), to read PDF content significantly hampered their scores on tasks where PDF information was crucial. This identifies a key feature gap for comprehensive research capabilities.
Closed models maintain a performance lead: Generally, closed-weight frontier models performed substantially better than open models for web research agents. However, DeepSeek R1 is noted as an interesting candidate for production use due to its speed and cost-effectiveness for high-volume, fast queries.
Efficiency doesn't always compromise accuracy: The study found that longer runtime was not generally associated with higher scores. Top performers like o3 and Gemini 2.5 Pro were often faster than average while achieving high accuracy, demonstrating that efficiency and performance can go hand-in-hand.
"Forgetting information" is a strong predictor of failure: Automated trace evaluation revealed that forgetting information is the strongest predictor of lower task scores in LLM agents, even more so than hallucinations or repeated tool calls. This suggests a critical area for improvement in agent memory and context management.
RetroSearch enables reliable benchmarking: The use of the RetroSearch environment provides a stable, frozen snapshot of the internet for evaluations, minimizing the variability caused by the continually changing live web. This is critical for consistently assessing model performance over time.
🚀 Use Cases
General web research for business intelligence:
Context: Answering broad, dynamic business questions like identifying companies in emerging sectors (e.g., nuclear fusion and their investors) or verifying industry rumors.
Motivation: To rapidly gather and synthesize disparate information from the web, accelerating market analysis and competitive intelligence efforts.
How it works: A leader poses a query to an LLM-powered chatbot. The LLM acts as an agent, executing search queries, reading web pages, and synthesizing the findings into a coherent answer.
Challenges: The LLM might provide plausible but incorrect information (hallucinations), struggle with complex search queries, or stop research prematurely.
Avoid Challenges: Prefer leading models like ChatGPT with o3 + web search, prompt them to double-check findings, and cross-verify critical information manually.
Implementation: Start with commercial tools for ease of use. For more tailored or sensitive queries, consider developing API-driven agents.
Competitive landscape mapping:
Context: Systematically compiling lists of entities, products, or events that fit specific, often ambiguous criteria (e.g., "major AI datacenters in the US" or "functioning satellites impacted by collisions").
Motivation: To thoroughly identify market players, technological trends, or historical incidents for strategic planning, due diligence, or risk assessment.
How it works: The LLM agent formulates search strategies, identifies potential candidates, and then verifies each candidate against a set of predefined inclusion criteria using web content.
Challenges: Determining when the list is exhaustive, discerning accurate verification information from unreliable sources, and managing the inherent ambiguity of "major" or "relevant".
Avoid Challenges: Accept that human oversight is often necessary for completeness and accuracy. Design tasks with clear inclusion criteria to minimize ambiguity.
Implementation: Leverage LLMs' ability to process large amounts of text. For high-stakes applications, combine LLM generation with human validation of each entry.
Structured data compilation for reporting:
Context: Automating the collection and organization of specific data points from various web sources into a structured format (e.g., "Software developer jobs in the US from 2019-2023" with specified columns).
Motivation: Streamline data collection for internal reports, industry analyses, or input for other analytical systems, saving significant manual effort.
How it works: The agent identifies relevant data sources, extracts specific numbers or text, and formats them into a predefined dataset structure, potentially performing calculations like "percent change".
Challenges: Agents may struggle with identifying nuanced data, combining information from disparate formats, or adapting their research plan when initial approaches fail.
Avoid Challenges: Provide very clear column definitions and examples. For complex derivations, break down the task into smaller "Find Number" or "Derive Number" sub-tasks.
Implementation: Utilize LLMs with strong "Compile Dataset" performance. For highly precise or complex datasets, API-driven agents offer more control over data extraction and validation logic.
Rapid claim validation and fact-checking:
Context: Quickly assessing the likelihood or veracity of a specific claim found online (e.g., "Tesla announced a 'Model H' car that would run on hydrogen fuel cells").
Motivation: To swiftly evaluate the credibility of information, crucial for combating misinformation, validating market intelligence, or making quick, informed decisions.
How it works: The agent gathers supporting or refuting evidence from web sources, judges the reliability of these sources, and then provides an estimated probability or assessment of the claim's truth.
Challenges: Agents can be gullible to low-quality sources, struggle with interpreting nuanced claims, or fail to apply sufficient skepticism.
Avoid Challenges: Frame queries to encourage the agent to identify source reliability. For critical claims, human experts must review the evidence and the LLM's assessment.
Implementation: While toolless agents can perform comparably to human analysts on some validation tasks, integrating web search provides real-time information.
Original source identification for due diligence:
Context: Tracing a published claim or statistic back to its initial, authoritative source (e.g., finding the original study cited in a news article about "AI Generated Propaganda").
Motivation: To ensure the accuracy and provenance of information, crucial for academic integrity, legal research, or verifying foundational data in strategic reports.
How it works: The agent traverses linked information, examining citation chains and publication timelines to identify the earliest, most authoritative origin of the claim.
Challenges: Distinguishing between a truly original source and an intermediate reference, navigating complex citation networks.
Avoid Challenges: For critical source verification, augment LLM output with human cross-referencing, especially when dealing with complex academic or legal citations.
Implementation: Focus on LLMs and agent configurations that demonstrate strong performance in "Find Original Source" tasks.
🛠️ Now / Next / Later
Now
Prioritize ChatGPT o3 + web search for general use: Make ChatGPT with o3 + web search your default tool for general web research, leveraging its leading performance and propensity for self-validation.
Rethink "Deep Research" mode defaults: Evaluate current usage of dedicated "Deep Research" branded tools, generally favoring regular chat modes with web search for their speed and flexibility, unless a specific tool like Gemini Deep Research consistently outperforms its chat counterpart for your specific needs.
Mandate human verification for critical outputs: Implement a robust human-in-the-loop verification process for all critical facts, numbers, or strategic conclusions generated by LLMs, acknowledging their persistent tendency to hallucinate and make reasoning errors.
Next
Pilot Claude 4 for custom agent development: Begin exploring and prototyping with Claude 4 Sonnet and Opus via API for developing tailored, more sophisticated research agents, particularly for tasks requiring advanced reasoning or iterative workflows.
Address PDF content ingestion gaps: Actively seek and integrate LLM solutions or third-party tools that provide robust PDF content reading and querying capabilities for your research agents, as this remains a notable limitation impacting comprehensive information gathering.
Initiate internal benchmark development: Start building specific internal benchmarks that reflect your organization's unique research challenges and data needs, mirroring the DRB methodology to quantitatively assess and improve the performance of LLM tools in your context.
Later
Invest in advanced agent architecture R&D: Allocate dedicated resources to researching and developing novel agent architectures that address fundamental LLM limitations in strategic planning, thoroughness, and dynamic adaptation, pushing beyond current "ReAct" paradigms.
Monitor open-weight model breakthroughs: Continuously track advancements in open-weight models like DeepSeek R1. As they close the performance gap, they could offer cost-effective, self-hostable solutions for high-volume, fast-query use cases, enabling new business models.
Prepare for AI-native UI interactions: Anticipate and prepare for the next generation of LLM capabilities that enable dynamic, human-like interaction with web pages (e.g., clicking links, navigating complex UIs), which will fundamentally transform the scope and efficiency of AI-powered research.






Share this post